通常要搜尋海量資料,我們會使用全文檢索,比對完全相同的關鍵字,現在有一個更好的選擇【語意搜尋】,它可以找出相似詞,再利用大型語言模型的問答(Q&A)功能從文件中找到答案。
類似全文檢索,先對文件進行編碼,將文字轉成向量,存入特殊結構的向量資料庫(Vector database),之後,我們就可以輸入【提示】,對向量資料庫進行查詢,架構如下: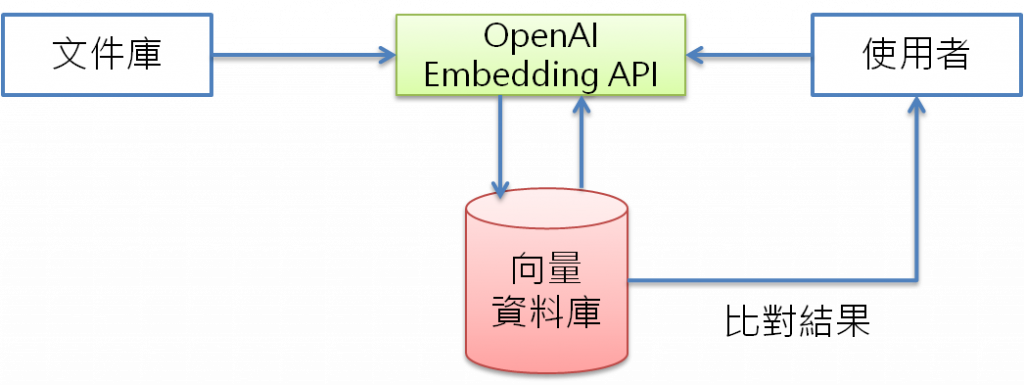
圖一. 語意搜尋
先安裝相關套件。
pip install langchain faiss-cpu
其中langchain是大型語言模型的擴充套件,Faiss是向量資料庫。
對文件進行編碼,將文件轉成向量。筆者自維基百科複製【中華民國歷史】內文,存成text變數。
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.callbacks import get_openai_callback
# split into chunks
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
# create embeddings
embeddings = OpenAIEmbeddings()
knowledge_base = FAISS.from_texts(chunks, embeddings)
# show user input
user_question = input("Ask a question:") # 辛亥革命發生在哪一年?
# 相似度比對,即語意搜尋
docs = knowledge_base.similarity_search(user_question)
# 利用大型語言模型的問答(Q&A)功能從文件中找到答案
llm = OpenAI()
chain = load_qa_chain(llm, chain_type="stuff")
with get_openai_callback() as cb:
response = chain.run(input_documents=docs, question=user_question)
print(response) # 辛亥革命發生在1911年
透過簡短的幾行程式就可以完成語意搜尋的功能,真是太舒服了,記得幾年前開發客服中心(Call center)的知識管理系統,客服人員整理了6000多條的問答,還蒐集許多的操作手冊、DM...,千辛萬苦的建入SharePoint,提供全文檢索的功能,結果還不能完全滿足現場客服人員(Agent)的需求,現在,有了語意搜尋及ChatGPT,可大幅提高搜尋的準確度。
以上程式只是一個很簡單的範例,實際上應用還需增加許多metadata,例如對應的文件名稱、存檔路徑、負責的業務部門...等等,結合關聯式資料庫,系統才會更具完整性。
另外,除了Faiss外,向量資料庫還有許多選擇,可參見OpenAI Embedding API文件說明。
OpenAI的進展非常快速,許多功能逐漸擴展,企業及個人應及早投入,畢竟【早起的鳥兒才有蟲吃】。
前文:
ChatGPT 應用系統開發(一)
ChatGPT 應用系統開發(二) -- 微調(Fine-tuning)企業專屬的模型
開發者必學:OpenAI API應用與開發。
ChatGPT企業實踐指南 | 技術透析與整合應用。
深度學習PyTorch入門到實戰應用。
ChatGPT 完整解析:API 實測與企業應用實戰。
Scikit-learn 詳解與企業應用。
開發者傳授 PyTorch 秘笈
深度學習 -- 最佳入門邁向 AI 專題實戰。
 I code so I am
I code so I am
